需要升级git内核程序的版本
作者归档:杨龙
过滤以不显示amq.gen-xxx队列,刷新会保留过滤
过滤以不显示amq.gen-xxx队列,刷新会保留过滤
^(?!amq\.gen\-).*$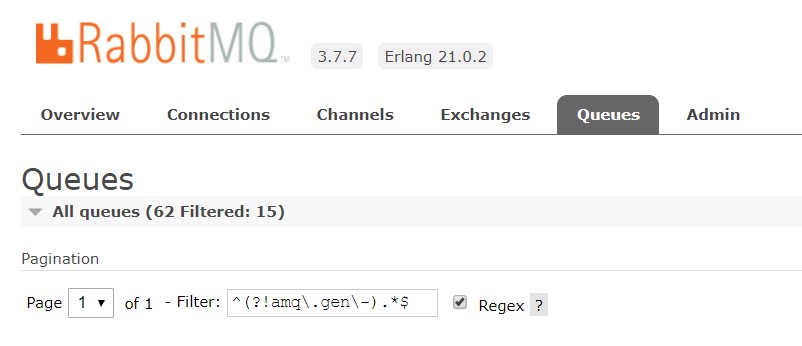
Nginx 快速解决静态文件POST 405 Not Allowed
error_page 405 =200 $uri;configure: WARNING: unrecognized options: –with-gd
使用–enable-gd 替代–with-gd
--with-gd becomes --enable-gd (whether to enable the extension at all) and --with-external-gd (to opt into using an external libgd, rather than the bundled one).
centos8 安装 oniguruma-devel
Package 'oniguruma', required by 'virtual:world', not found
configure: error: Package requirements (oniguruma) were not met:
需要使用这个命令安装
dnf --enablerepo=PowerTools install oniguruma-devel或(如果报错)
dnf --enablerepo=powertools install oniguruma-devel如果是 rockylinux:
dnf install --enablerepo=devel -y oniguruma-devel
MySQL 5.5 Reference Manual / Functions and Operators / Encryption and Compression Functions 12.13 Encryption and Compression Functions
在 CDATA 节中找到无效的 XML 字符 (Unicode: 0x1f)
https://blog.csdn.net/dufufd/article/details/53895764
在 CDATA 节中找到无效的 XML 字符 (Unicode: 0x1f)
String could not be parsed as XML
解析XML文件时,会碰到程序发生以下一些异常信息:
在 CDATA 节中找到无效的 XML 字符 (Unicode: 0x1f)。
或者:
An invalid XML character (Unicode: 0x1f) was found in the CDATA section.
这些错误的发生是由于一些不可见的特殊字符的存在,而这些字符对于XML文件来说又是非法的,所以XML解析器在解析时会发生异常,官方定义了XML的无效字符分为三段:
0x00 – 0x08
0x0b – 0x0c
0x0e – 0x1f
解决方法是:在解析之前先把字符串中的这些非法字符过滤掉即可, 不会影响原来文本的内容。
即:string.replaceAll(“[\\x00-\\x08\\x0b-\\x0c\\x0e-\\x1f]”, “”) ;
# php 版过滤方法
$content2 = preg_replace(‘/[\\x00-\\x08\\x0b-\\x0c\\x0e-\\x1f]/mu’, ”, $content);
另外:这些字符即使放在CDATA中仍然解析不了,所以最好的办法是过滤掉。
Linux 系统 /var/log/journal/ 垃圾日志清理
2、journalctl 命令自动维护文件大小
1)只保留近一周的日志
journalctl --vacuum-time=1w
2)只保留500MB的日志
journalctl --vacuum-size=500M浮点数格式与存储
计算机中的数分为整数与实数。对于实数,绝大多数现代的计算机系统采纳了所谓的浮 点数表达方式。 这种表达方式利用科学计数法来表达实数,即用一个尾数(Mantissa ), 一 个基数(Base),一个指数 e(阶码 E=e+127 或者 e+1023)(exponent)以及一个表示正负 的符号(Sign)来表达实数。 比如 123.45 用十进制科学计数法可以表达为 1.2345 × 10^2 , 其中 1.2345 为尾数,10 为基数,2 为指数。 浮点数利用指数达到了浮动小数点的效果, 从而可以灵活地表达更大范围的实数。 又对于一个二进制的数比如 1011.01,用科学计数 法也可以表示为:1.01101*2^3,其中 1.1101 为尾数,2 为基数,3 为指数。
一,浮点数的存储方法
计算机中是用有限的连续字节保存浮点数的。 保存这些浮点数当然必须有特定的格式, C/C++中的浮点数类型 float 和 double 采纳了 IEEE 754 标准中所定义的单精度 32 位 浮点数和双精度 64 位浮点数的格式。 在 IEEE 标准中,浮点数是将特定长度的连续字节 的所有二进制位分割为特定宽度的符号域,指数域和尾数域三个域, 其中保存的值分别用 于表示给定二进制浮点数中的符号,指数和尾数。 这样,通过尾数和可以调节的指数(所 以称为”浮点”)就可以表达给定的数值了。
根据国际标准 IEEE 754,任意一个二进制浮点数 V 可以表示成下面的形式:
V = (-1) ^ s × M × 2 ^ E
(1)(-1)^s 表示符号位,当 s=0,V 为正数;当 s=1,V 为负数。
(2)M 表示有效数字,大于等于 1,小于 2,但整数部分的 1 不变,因此可以省略。
(3)2^E 表示指数位。
比如: 对于十进制的 5.25 对应的二进制为:101.01,相当于:1.0101*2^2。所以,S 为 0,M 为 1.0101,E 为 2。 而-5.25=-101.01=-1.0101 *2^2.。所以 S 为 1,M 为 1.0101,E 为 2。
对于 32 位的单精度数来说,从低位到高位,尾数 M 用 23 位来表示,阶码 E 用 8 位来表示, 而符号位用最高位 1 位来表示,0 表示正,1 表示负。对于 64 位的双精度数来说,从低位 到高位,尾数 M 用 52 位来表示,阶码用 11 位来表示,而符号位用最高位 1 位来表示,0 表示正,1 表示负。
IEEE 754 对有效数字 M 和指数 E,还有一些特别规定。 前面说过,M 可以写成 1.xxxxxx 的形式,其中 xxxxxx 表示小数部分。IEEE 754 规定,在计算机内部保存 M 时,默认这个 数的第一位总是 1,因此可以被舍去,只保存后面的 xxxxxx 部分。比如保存 1.0101 的时候, 只保存 0101,等到读取的时候,再把第一位的 1 加上去。这样做的目的,是节省 1 位有效 数字。以 32 位浮点数为例,留给 M 只有 23 位,将第一位的 1 舍去以后,等于可以保存 24 位有效数字。
对于 E, 首先,E 为一个无符号整数(unsigned int)。这意味着,如果 E 为 8 位,它的取 值范围为 0~255;如果 E 为 11 位,它的取值范围为 0~2047。然而科学计数法中的 E 是可 以出现负数的,所以 IEEE 754 规定,E 的真实值必须再减去一个中间数,对于 8 位的 E, 这个中间数是 127;对于 11 位的 E,这个中间数是 1023。 比如,2^2 的 E 是 2,所以保 存成 float 32 位浮点数时,必须保存成 2+127=129,即 10000001。
此外,E 还需要考虑下面 3 种情况:
(1)E 不全为 0 或不全为 1。这时,浮点数就采用上面的规则表示,即指数 E 的计算值减 去 127(或 1023),得到真实值,再将有效数字 M 前加上第一位的 1。
(2)E 全为 0。这时,浮点数的指数 E 等于 1-127(或者 1-1023),有效数字 M 不再加上 第一位的 1,而是还原为 0.xxxxxx 的小数。这样做是为了表示±0,以及接近于 0 的很小的 数字。
(3)E 全为 1。这时,如果有效数字 M 全为 0,表示±无穷大(正负取决于符号位 s);如 果有效数字 M 不全为 0,表示这个数不是一个数(NaN)。
二,浮点数的转换方法
浮点数的转换方法可以分为如下 2 种情况:
1.给出一个浮点数,计算对应的二进制 比如给定一个浮点数,7.25,如何计算它对应的单精度和双精度的二进制呢?
首先,十进制浮点数 7.25 对应的二进制(二进制,十进制和十六进制转化方法:点击这里) 为:111.01。用二进制的科学计数法为:1.1101*2^2。所以,按照上面浮点数的存储结构, 得出符号位为: 0,表示正数;阶码(指数) E 单精度为 2+127=129,双精度为 2+1023=1025; 小数部分 M 为:1101。 所以,
单精度的二进制位:0 10000001 1101 0000000000000000000;
双 精 度 的 二 进 制 位 : 0 10000000001 1101 000000000000000000000000000000000000000000000000
第一步:将 178.125 表示成二进制数:(178.125)(十进制数)=(10110010.001)(二进制形式);
第二步:将二进制形式的浮点实数转化为规格化的形式:(小数点向左移动 7 个二进制位可以 得到)
10110010.001=1.0110010001*2^7 因而产生了以下三项:
符号位:该数为正数,故第 31 位为 0,占一个二进制位.
阶码:指数(e)为 7,故其阶码为 127+7=134=(10000110)(二进制),占从第 30 到第 23 共 8 个 二进制位.
(注:指数有正负即有符号数,但阶码为正即无符号数,所以将 e 加个 127 作为偏移,方 便指数的比较)
尾数为小数点后的部分, 即 0110010001.因为尾数共 23 个二进制位,在后面补 13 个 0,即 01100100010000000000000
所以,178.125 在内存中的实际表示方式为:
0 10000110 01100100010000000000000
2.给出一个浮点数的二进制,计算对应的十进制值
而如果而如果给出了一个浮点数的二进制,如何计算它对应的十进制,其实就是 1 中的逆 运算。分别求出对应的符号位,阶码指数 E 和小数 M 部分,就可以了。比如,给定一个单 精度浮点数的二进制存储为: 0 10000001 1101 0000000000000000000; 那么对应的符号为:0,表示正数;阶码 E 为:129-127=2;尾数为 1.1101。所以对应的二 进制科学计数法为:1.1101*2^2,也就是 111.01 即:7.25。
小数的输出
小数也可以使用 printf 函数输出,包括十进制形式和指数形式,它们对应的格式控制符分别是:
%f 以十进制形式输出 float 类型;
%lf 以十进制形式输出 double 类型;
%e 以指数形式输出 float 类型,输出结果中的 e 小写;
%E 以指数形式输出 float 类型,输出结果中的 E 大写;
%le 以指数形式输出 double 类型,输出结果中的 e 小写;
%lE 以指数形式输出 double 类型,输出结果中的 E 大写。
对代码的说明:
%f 和 %lf 默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。
将整数赋值给 float 变量时会变成小数。
以指数形式输出小数时,输出结果为科学计数法;也就是说,尾数部分的取值为:0 ≤ 尾数 < 10。
另外,小数还有一种更加智能的输出方式,就是使用%g。%g 会对比小数的十进制形式和指数形式,以最短的方式来输出小数,让输出结果更加简练。所谓最短,就是输出结果占用最少的字符。
%g 使用示例:
运行结果:
a=1e-05
b=3e+07
c=12.84
d=1.22934
对各个小数的分析:
a 的十进制形式是 0.00001,占用七个字符的位置,a 的指数形式是
1e-05,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
b 的十进制形式是 30000000,占用八个字符的位置,b 的指数形式是 3e+07,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
c 的十进制形式是 12.84,占用五个字符的位置,c 的指数形式是 1.284e+01,占用九个字符的位置,十进制形式较短,所以以十进制的形式输出。
d 的十进制形式是 1.22934,占用七个字符的位置,d 的指数形式是 1.22934e+00,占用十一个字符的位置,十进制形式较短,所以以十进制的形式输出。
读者需要注意的两点是:
%g 默认最多保留六位有效数字,包括整数部分和小数部分;%f 和 %e 默认保留六位小数,只包括小数部分。
%g 不会在最后强加 0 来凑够有效数字的位数,而 %f 和 %e 会在最后强加 0 来凑够小数部分的位数。
总之,%g 要以最短的方式来输出小数,并且小数部分表现很自然,不会强加零,比 %f 和 %e 更有弹性,这在大部分情况下是符合用户习惯的。
除了 %g,还有 %lg、%G、%lG:
%g 和 %lg 分别用来输出 float 类型和 double 类型,并且当以指数形式输出时,e小写。
%G 和 %lG 也分别用来输出 float 类型和 double 类型,只是当以指数形式输出时,E大写。
————————————————
版权声明:本文为CSDN博主「洛铭」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42528287/article/details/85696940
原码反码补码的相互转换
原码反码补码的相互转换
首先,正数的原码,反码,补码都是相同的。
所以,这里讨论负数的原码,反码,补码的相互转化问题。
1. 负数原码和反码的相互转化
负数原码转化为反码:符号位不变,数值位按位取反。
如:
原码 1100 0010 反码 1011 1101
负数反码转化为原码:符号位不变,数值位按位取反。
反码 1011 1101 原码 1100 0010
2. 负数原码和补码的相互转化
负数原码转化为补码:符号位不变,数值位按位取反,末尾加一。
原码 1100 0010 反码 1011 1101 //符号位不变,数值位按位取反 补码 1011 1110 //末尾加1
负数补码转化为原码:符号位不变,数值位按位取反,末尾加1。
补码 1011 1110
1100 0001 //符号位不变,数值位按位取反
原码 1100 0010 //末尾加1
3.负数反码和补码的相互转化
负数反码转化为补码:末尾加1。
反码 1011 1101 补码 1011 1110
负数补码转化为反码:末尾减1(注意,此处的反码是指原码的反码)。
补码 1011 1110 原码的反码 1011 1101 //减法 借位
4.总结
正数的原码、反码和补码都相同。
负数原码和反码的相互转换:符号位不变,数值位按位取反。
负数原码和补码的相互转换:符号位不变,数值位按位取反,末位再加1。